HybrA-Filterbanks¶
Auditory-inspired filterbanks for deep learning
Welcome to HybrA-Filterbanks, a PyTorch library providing state-of-the-art auditory-inspired filterbanks for audio processing and deep learning applications.
Overview¶
This library contains the official implementations of:
ISAC (paper): Invertible and Stable Auditory filterbank with Customizable kernels for ML integration
HybrA (paper): Hybrid Auditory filterbank that extends ISAC with learnable filters
ISACSpec: Spectrogram variant with temporal averaging for robust feature extraction
ISACCC: Cepstral coefficient extractor for speech recognition applications
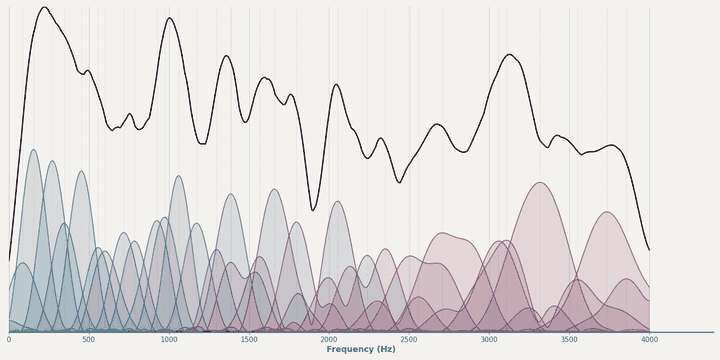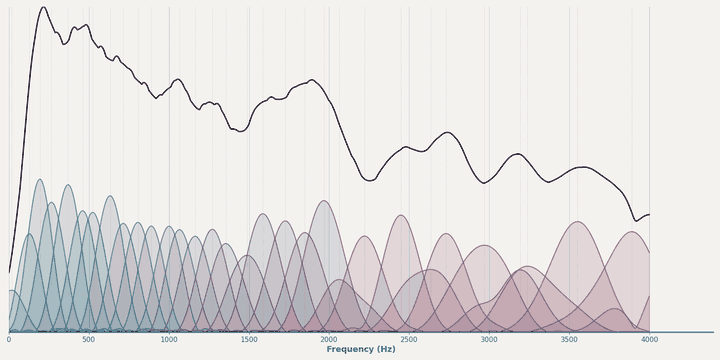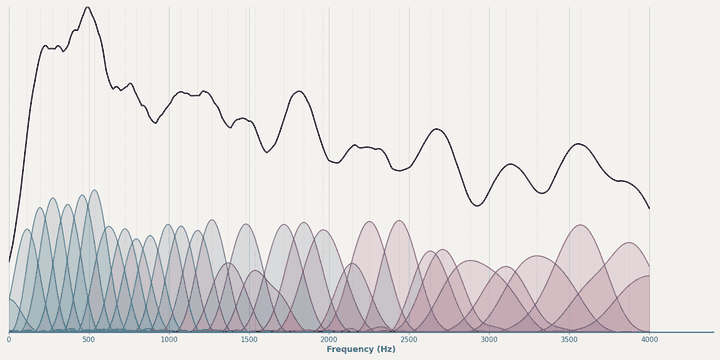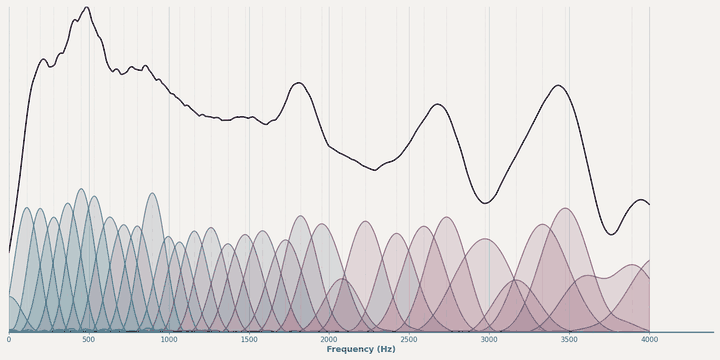
Magnitude learning dynamics of HybrA during training.¶
Key Features¶
✨ PyTorch Integration: All filterbanks are implemented as nn.Module for seamless integration into neural networks
🎯 Auditory Modeling: Based on human auditory perception principles (mel, ERB, bark scales)
⚡ Fast Implementation: Optimized using FFT-based circular convolution
🔧 Flexible Configuration: Customizable kernel sizes, frequency ranges, and scales
📊 Frame Theory: Built-in functions for frame bounds, condition numbers, and stability analysis
🎨 Visualization: Rich plotting capabilities for filter responses and time-frequency representations
Installation¶
We publish all releases on PyPI. You can install the current version by running:
pip install hybra
Quick Start¶
Basic ISAC Filterbank¶
1import torch
2from hybra import ISAC
3
4# Create ISAC filterbank
5filterbank = ISAC(
6 kernel_size=128,
7 num_channels=40,
8 fs=16000,
9 L=16000,
10 scale='mel'
11)
12
13# Process audio signal
14x = torch.randn(1, 16000) # Random signal for demo
15coefficients = filterbank(x)
16reconstructed = filterbank.decoder(coefficients)
17
18# Visualize
19filterbank.plot_response()
20filterbank.ISACgram(x, log_scale=True)
HybrA with Learnable Filters¶
1from hybra import HybrA
2
3# Create hybrid filterbank with learnable components
4hybrid_fb = HybrA(
5 kernel_size=128,
6 learned_kernel_size=23,
7 num_channels=40,
8 fs=16000,
9 L=16000
10)
11
12# Forward pass (supports gradients)
13x = torch.randn(1, 16000, requires_grad=True)
14y = hybrid_fb(x)
15
16# Check condition number for stability
17print(f"Condition number: {hybrid_fb.condition_number():.2f}")
ISAC Spectrograms and MFCCs¶
1from hybra import ISACSpec, ISACCC
2
3# Spectrogram with temporal averaging
4spectrogram = ISACSpec(
5 num_channels=40,
6 fs=16000,
7 L=16000,
8 power=2.0,
9 is_log=True
10)
11
12# MFCC-like cepstral coefficients
13mfcc_extractor = ISACCC(
14 num_channels=40,
15 num_cc=13,
16 fs=16000,
17 L=16000
18)
19
20x = torch.randn(1, 16000)
21spec = spectrogram(x)
22mfccs = mfcc_extractor(x)
It is also straightforward to include them in any model, e.g., as an encoder/decoder pair.
1import torch
2import torch.nn as nn
3import torchaudio
4from hybra import HybrA
5
6class Net(nn.Module):
7 def __init__(self):
8 super().__init__()
9
10 self.linear_before = nn.Linear(40, 400)
11
12 self.gru = nn.GRU(
13 input_size=400,
14 hidden_size=400,
15 num_layers=2,
16 batch_first=True,
17 )
18
19 self.linear_after = nn.Linear(400, 600)
20 self.linear_after2 = nn.Linear(600, 600)
21 self.linear_after3 = nn.Linear(600, 40)
22
23
24 def forward(self, x):
25
26 x = x.permute(0, 2, 1)
27 x = torch.relu(self.linear_before(x))
28 x, _ = self.gru(x)
29 x = torch.relu(self.linear_after(x))
30 x = torch.relu(self.linear_after2(x))
31 x = torch.sigmoid(self.linear_after3(x))
32 x = x.permute(0, 2, 1)
33
34 return x
35
36class HybridfilterbankModel(nn.Module):
37 def __init__(self):
38 super().__init__()
39
40 self.nsnet = Net()
41 self.fb = HybrA()
42
43 def forward(self, x):
44 x = self.fb(x)
45 mask = self.nsnet(torch.log10(torch.max(x.abs()**2, 1e-8 * torch.ones_like(x, dtype=torch.float32))))
46 return self.fb.decoder(x*mask)
47
48if __name__ == '__main__':
49 audio, fs = torchaudio.load('your_audio.wav')
50 model = HybridfilterbankModel()
51 model(audio)
Citation¶
If you find our work valuable, please cite
@article{HaiderTight2024,
title={Hold me Tight: Trainable and stable hybrid auditory filterbanks for speech enhancement},
author={Haider, Daniel and Perfler, Felix and Lostanlen, Vincent and Ehler, Martin and Balazs, Peter},
journal={arXiv preprint arXiv:2408.17358},
year={2024}
}
@article{HaiderISAC2025,
title={ISAC: An Invertible and Stable Auditory Filter Bank with Customizable Kernels for ML Integration},
author={Daniel Haider and Felix Perfler and Peter Balazs and Clara Hollomey and Nicki Holighaus},
year={2025},
url={arXiv preprint arXiv:2505.07709},
}
Links: